最新小红书图文和视频作品采集工具
小红书采集工具
采集小红书图文/视频作品信息
获取小红书图文/视频作品下载地址
下载小红书图文/视频作品文件
🥣 使用方法
如果仅需下载作品文件,选择 直接运行 或者 源码运行 均可,如果需要获取作品信息,则需要进行二次开发进行调用。
🖱 直接运行
前往 Releases 下载程序压缩包,解压后打开程序文件夹,双击运行 main.exe 即可使用。
⌨️ 源码运行
安装版本号不低于 3.10 的 Python 解释器
安装 requirements.txt 包含的第三方模块
下载本项目最新的源码或 Releases 发布的源码至本地
运行 main.py 即可使用
💻 二次开发
如果想要获取小红书图文/视频作品信息,可以根据 main.py 的注释提示进行代码调用。
#测试链接
error_demo = “https://github.com/JoeanAmier/XHS_Downloader"
image_demo = “https://www.xiaohongshu.com/explore/63b275a30000000019020185"
video_demo = “https://www.xiaohongshu.com/explore/64edb460000000001f03cadc"
#实例对象
1 | path = "" # 作品下载储存根路径,默认值:当前路径 |
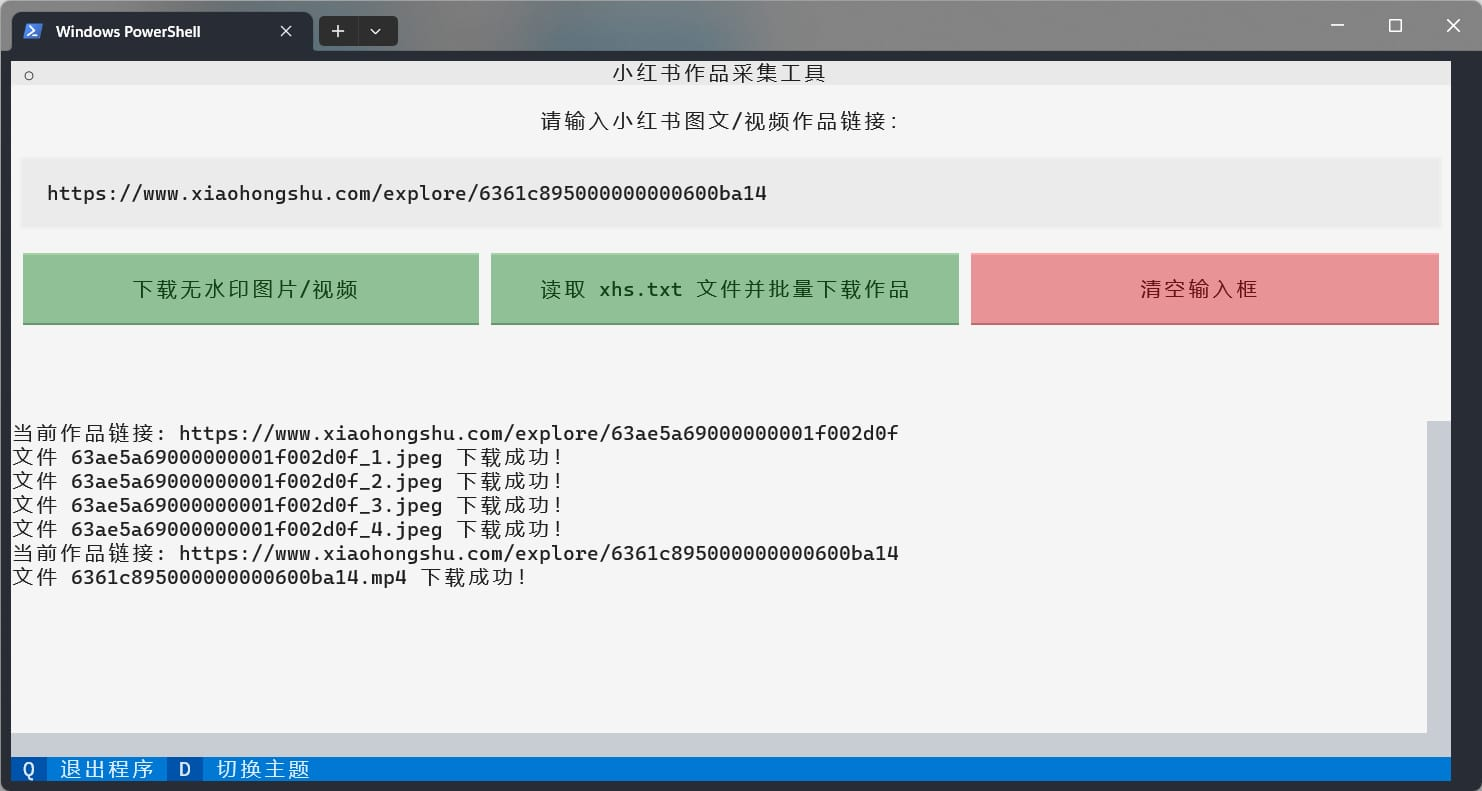
⛓ 批量下载
在程序所在文件夹创建一个 xhs.txt 文本文件,然后将待处理的作品链接输入文件,每行输入一个作品链接,编辑完成后保存文件,然后运行程序,点击 读取 xhs.txt 文件并批量下载作品 按钮,程序会批量下载每个链接对应的作品文件。
⚙️ 配置文件
根目录下的 settings.json 文件,可以自定义部分运行参数。
参数 类型 含义 默认值
path str 作品文件储存根路径 项目根路径
folder str 作品文件储存文件夹名称 Download
cookie str 小红书网页版 Cookie,无需登录;建议自行设置 内置 Cookie
proxies str 设置代理 无
timeout int 请求数据超时限制,单位:秒 10
chunk int 下载文件时,每次从服务器获取的数据块大小,单位:字节 262144(256KB)
🌐 Cookie
打开浏览器(可选无痕模式启动),访问小红书任意网页
按 F12 打开开发人员工具
选择 控制台 选项卡
输入 document.cookie 后回车确认
输出内容即为所需 Cookie